태터툴즈(tattertools) 설치하기 & 글 남기기 | 오토셋 올가 4.2.x
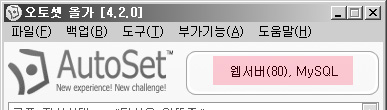
1. 설치를 위한 준비 오토셋설치폴더\Server\Apache2\conf\httpd.conf 파일을 EditPlus 또는 메모장으로 열어줍니다. Ctrl + G 키를 눌러, 73 을 입력하여 73번째 줄로 이동합니다. 아래이 그림과 같이 AllowOverride None 이라고 된 것이 있습니다. None 을 지우고, FileInfo 를 적어주고 저장을 합니다. ** 참고 : 오토셋 올가 4.2.3 버전 이상의 경우, 이 과정은 생략합니다. 그리고 오토셋에서 웹 서버가 이미 작동중이었다면, [재시작] 을 아직 실행되지 않았다면, [웹 서버 시작] 을 해줍니다. MySQL 서버도 시작해줍니다. 위와 같이 모니터 창에 웹서버(포트번호), MySQL 이라고 뜨는 것을 확인하고, 설치를 따라해봅니다. 2. 태터..